
537 posts

Choosing A Terminal for my Ubuntu Linux — Ghostty, Kitty, Alacritty & GNOME Terminal
I use and love the stock Terminal app in Ubuntu (GNOME Terminal) but I want to have another efficient/performant alternative. So, I am exploring to find the suitable one and gain more knowledge and …
[guide] How to completely remove Snap from Ubuntu ?
I have a laptop with Microsoft Windows 11 Pro installed and a WSL with the default Ubuntu distribution. It is preconfigured with Snap package manager. But I am not using Snap in Ubuntu WSL. So I feel …
What I do after installing Ubuntu as a SWE
I mainly develop software on Ubuntu. Ubuntu is my daily driver for Android app development, Go web development, Laravel full stack web development, and Go CLI app development. In this blog post, I …
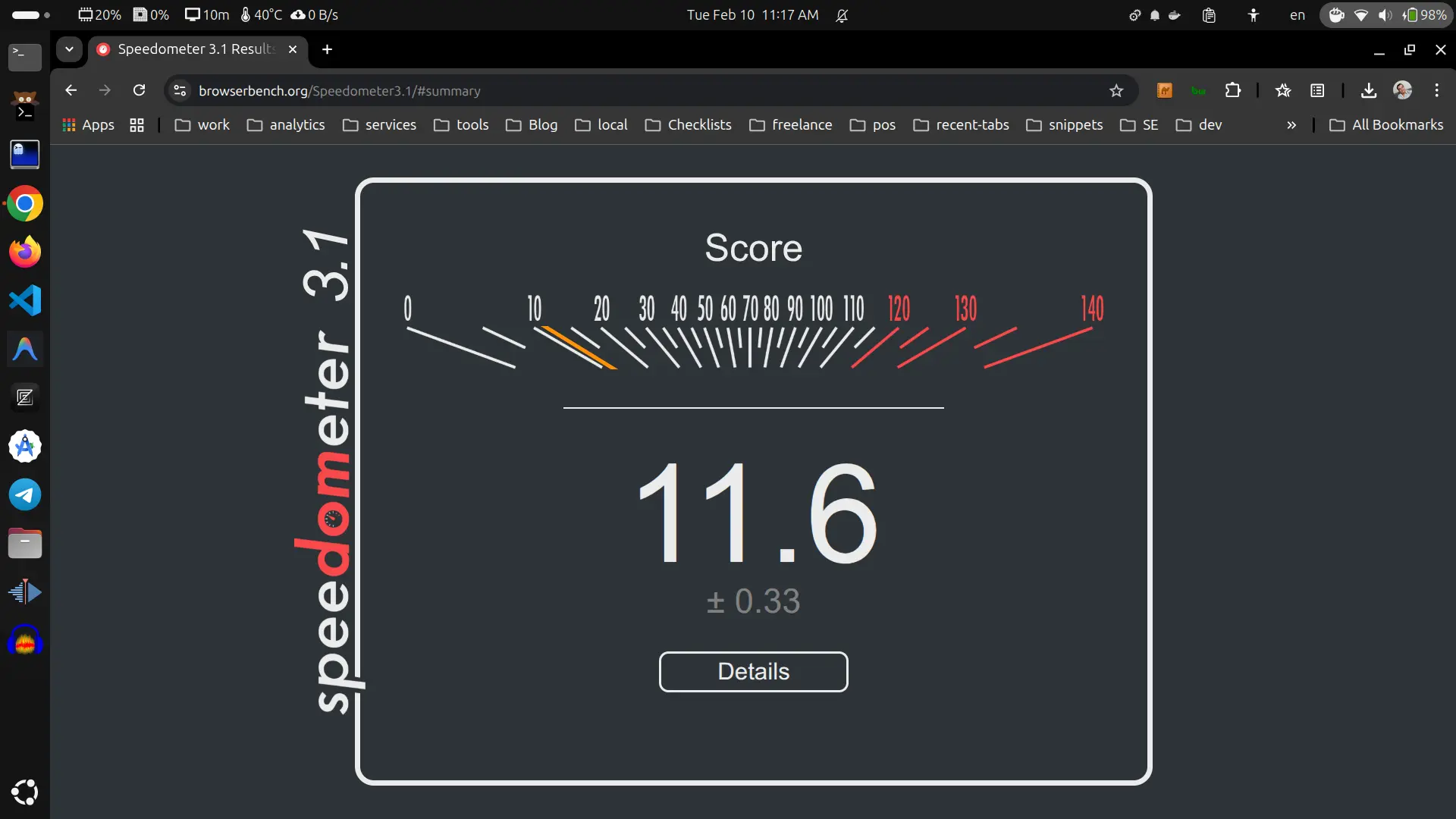
Benchmarking Ubuntu vs Windows on the same HP ZBook
Laptop specs 🔗 I have an HP ZBook 15 G3 with HP 80D5 motherboard. CPU Information (processor): item info Name Intel Core i7-6820HQ Topology 1 Processor, 4 Cores, 8 Threads Identifier GenuineIntel …
![[fixed] After upgrading Ubuntu Linux Kernel, Panic!](/img/ubuntu_kernel_panic.jpg)
[fixed] After upgrading Ubuntu Linux Kernel, Panic!
I updated the index of programs via sudo apt update, then did a full upgrade using this command sudo apt full-upgrade. It errors! After restarting the kernel panicked. Linux kernel panic 🔗 Here is the …
Stop Memorizing Package Managers: Meet `i`, The Ultimate Abstraction Layer
If you are a developer or a Linux enthusiast who frequently switches between distributions or operating systems, you know the pain. One day you are on Ubuntu typing sudo apt install, the next you are …
Speed Up Windows 10/11: Set Background Services to Manual (On‑Demand)
In this part of the debloat series, we’ll tune Windows services so they don’t run all the time, but still start automatically when needed. Instead of aggressively disabling everything, …
Take Back Your Data: How to Disable Telemetry in Windows 10 & 11 (Safely)
Windows 10 and 11 constantly send telemetry and diagnostic data back to Microsoft to “improve the experience”, but many users see it as unnecessary tracking and bandwidth waste. In this …
Stop Bing Clutter: How to Remove Web Results from Windows 11/10 Start Menu
If you’ve ever searched for a file or app from the Windows Start Menu only to get web results from Bing, you’re not alone. Microsoft’s Start Menu tries to be helpful by showing …
How to optimize site content for LLM search ?
Getting your business recommended in LLM answers is about becoming the “obvious” and low‑ambiguity option for specific questions buyers ask AI tools. This blog post walks you through the whole …